Batch and accurately convert PDF to Markdown format and recognize tables
2025-07-16
At the beginning of the year, I looked for some methods to extract images, text, tables, and formulas in detail from PDF documents. I found some traditional tools related to layout analysis, such as layout-parser, PaddleOCR(Layout analysis).
However, it is found that it cannot fully meet the needs,
For example, this is the result of Paddle OCR:

This is the result of Layout-Parser:
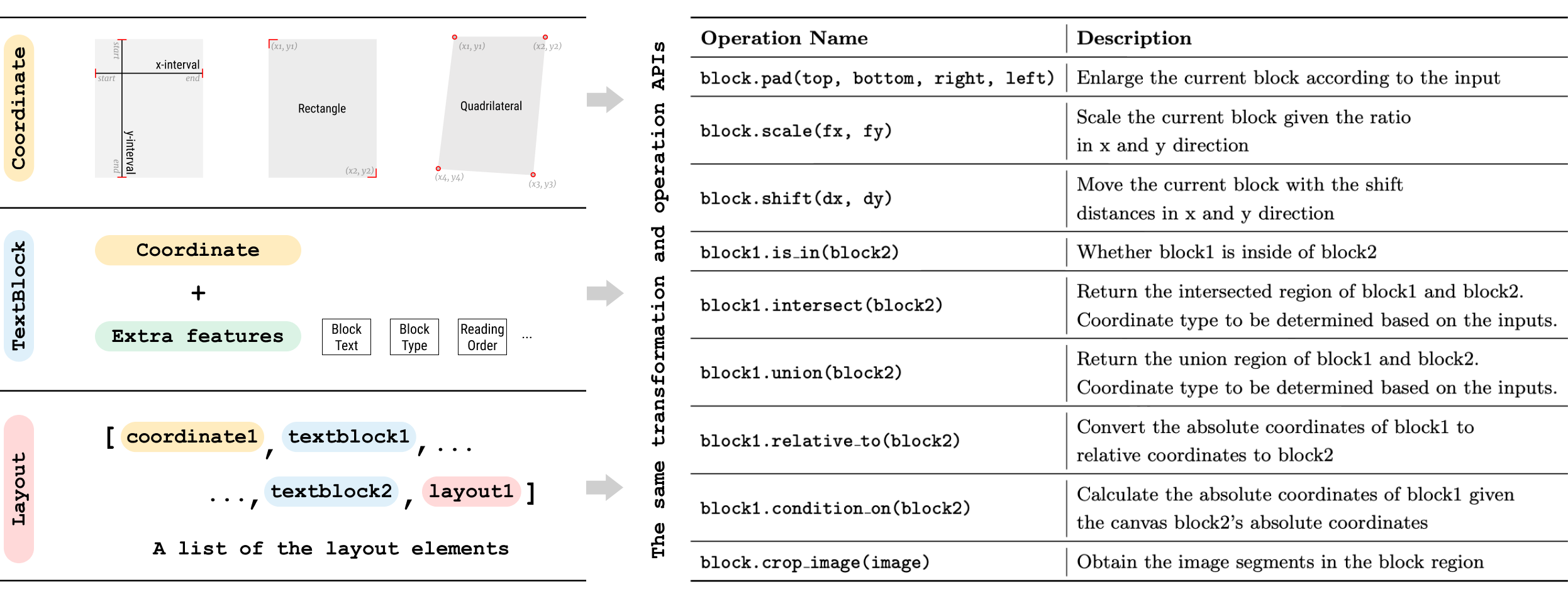
However, the marker demonstrates better balanced performance, effectively capturing text, images, and table information from the PDF.
For example:
Original:
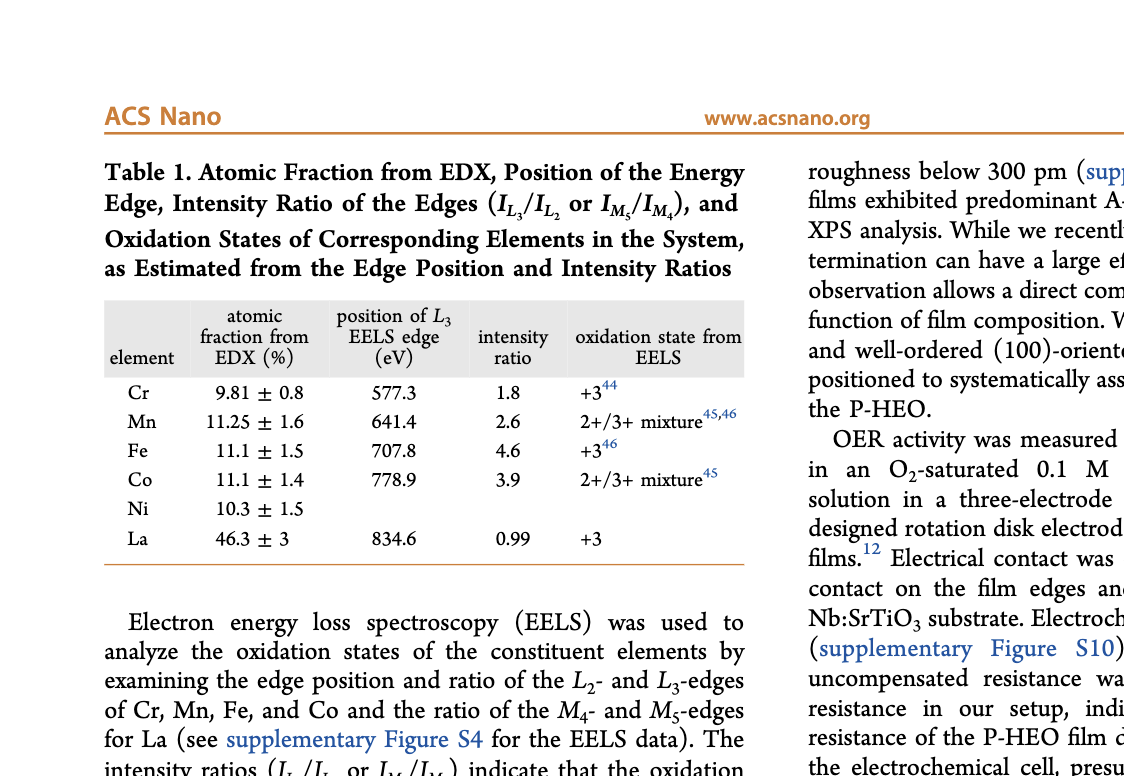
Analyzed:
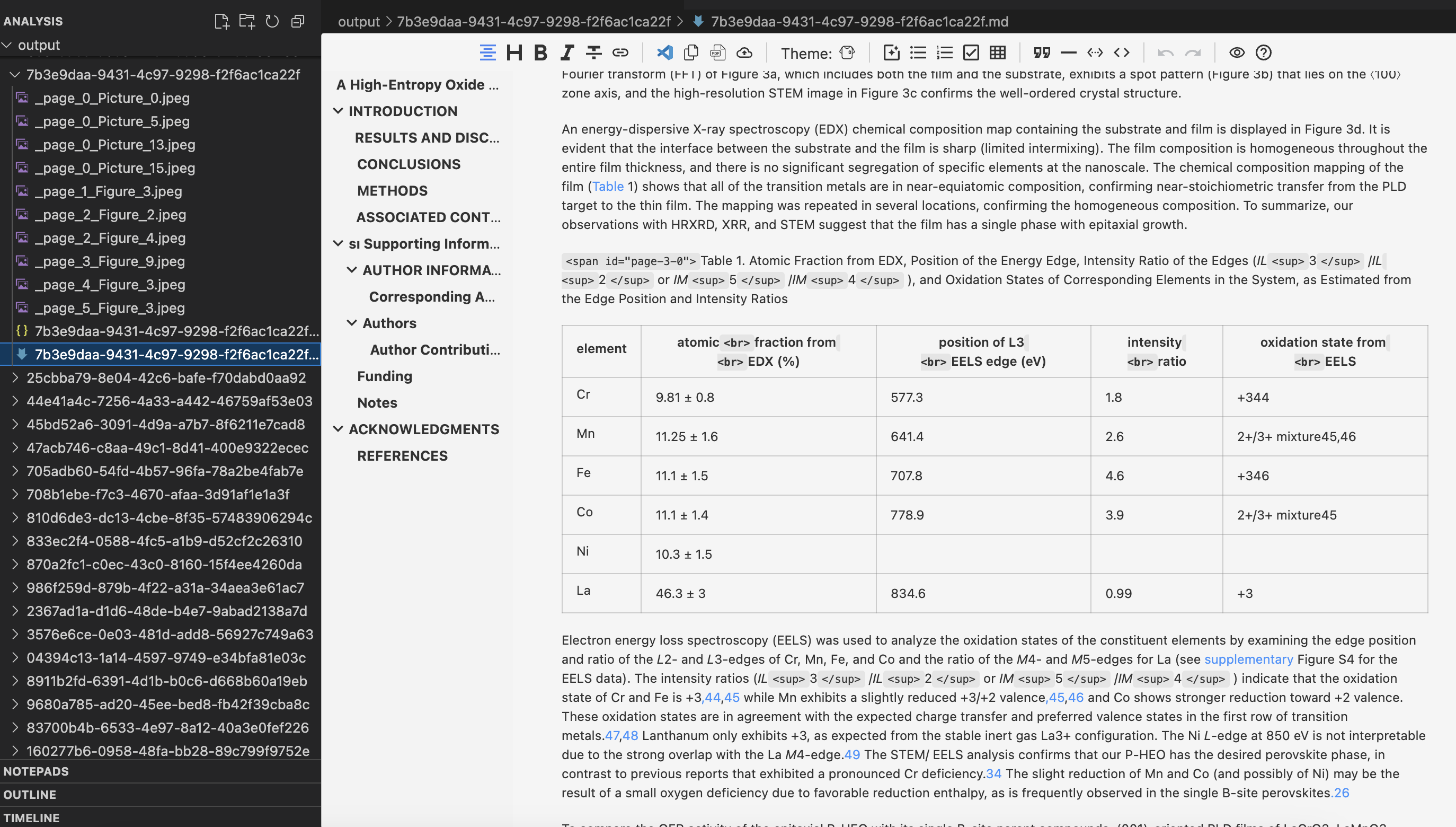
To massive process the files, it's better to use high-performance GPU to speed up.
Optimized batch processing script: batch_convert_optimized.py
You need to install the dependencies before use
python 3.10+ and PyTorch:
Then:
pip install marker-pdf
pip install marker-pdf[full]